Navigation
- Kanamaru Lab., Kogakuin Univ.
Smartphones and sigle board computers
Image Processing System
Reinforcement Learning for Biped Robots
Learning the control of the biped robot
 Let us consider movements of human, such as biped walking.
Let us consider movements of human, such as biped walking.
Although there are several conditions for walking, such as "walking on the flat ground", "walking on the graveled ground", "ascending/descending the stairs", "going up/down the slope", and so on, we can walk stably regardless of the conditions.
This is because we have been learning how to walk adapting to the environments for a long period. We have been learning how to walk since we were about 1 year old.
Then, can robots also walk adapting to the several environments?
The answer may depend on the performance of the robot, but, in almost all the cases, it is difficult for the robot to walk in unexpected environments.
 Therefore, if the robots are required to work in various environments,
many rules for controlling in those environments should be prepared in advance.
This would be a very hard task.
Therefore, if the robots are required to work in various environments,
many rules for controlling in those environments should be prepared in advance.
This would be a very hard task.
Can't robots move adapting to the environment like human? Can't robots learn how to move and how to process the information like human?
The theories of neural networks and machine learning treat such problems. In our laboratory, we use a method called reinforcement learning, and we try to construct a model which learn how to walk with trial and error like human.
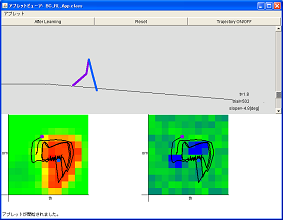
The figures show applications to simulate the walking of a biped robot programmed in this laboratory. The upper application was written in Java (simulator), and the right application was written using Visual C++. In this applications, the state of the robot is represented by 6 angles, i.e., the position (x,y) of the waist, two angles of thighs, and two angles of ankles, and their equations of motion are numerically solved.
These applications correspond to the brain of the robot which examines how to walk.
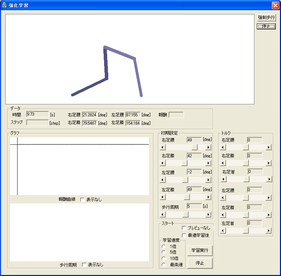
 The figure (left) shows an application
programmed with Linux and Qt4 library by French student Laurent Verdoïa
from ESIEE Paris
who stayed in Japan from May 2007 to August 2007,
that was built to obtain appropriate inputs to the bipedal robot.
The figure (left) shows an application
programmed with Linux and Qt4 library by French student Laurent Verdoïa
from ESIEE Paris
who stayed in Japan from May 2007 to August 2007,
that was built to obtain appropriate inputs to the bipedal robot.
An English scientist Alan Turing stated that "the brain looks more like cold porridge than like a machine". As you know, the cold-porridge-like brain can perform various tasks such as walking, thinking, information processing, and so on.
Our laboratory tries to understand how the brain works in detail.
For further information about the reinforcement learning, please see:
- Reinforcement Learning for CPG-controlled Bipedal Walking
- Cart-Pole Balancing by Reinforcement Learning
- Swinging up a Pendulum by Reinforcement Learning
- Takashi Kanamaru, "van der Pol oscillator," Scholarpedia (2007) 2(1):2202.
Circuit for the biped robot
 Although we utilize the robot on the market,
to move it as we like from the computer,
several peripheral circuits are required.
For the joints of the robot,
we use the servo motors for RC cars, and
they need PWM signals.
Although we utilize the robot on the market,
to move it as we like from the computer,
several peripheral circuits are required.
For the joints of the robot,
we use the servo motors for RC cars, and
they need PWM signals.
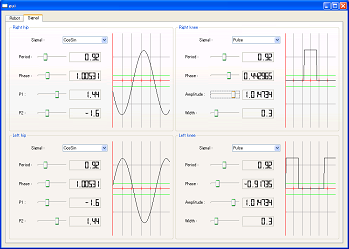
To generate PWM signals, there are several methods such as using the FPGAs. We created a simple circuit with a PIC microcomputer. The widths of PWM signals are determined by the outputs of van der Pol equations which are known to generate oscillations.
As for van der Pol equation, please see "van der Pol oscillator" written by T. Kanamaru at Scholarpedia.
We use the servo motors sold by Kondo Kagaku, and we can perform both the operation and the state-acquisition, which are shown in the left figure of the oscilloscope.
These servo motors and microcomputers correspond to the muscles and nerves for the robot.