人物のポーズ認識について
本ページでは、MediaPipe により人物の骨格認識をした後、その結果をもとに人物のポーズを分類する方法を解説する。
「ポーズを分類する」ことの例としては、去年の卒論にあった
「直立」、「右手前」、「左手前」、「両手腰」、
の4種を分類することが例として挙げられる。
卒論を読んだだけではわからなかったかもしれないが、これらは「静止したポーズ」をポーズとして定義している。
なお、卒論の例はポーズ認識としてはやや簡単である。なぜなら、両手の y 座標を観察するだけで5つのポーズをある程度分類できるからである。
より「難しそう」なポーズの分類としては、「平成仮面ライダーの変身ポーズの分類」などが挙げられる。
これは、両手の y 座標を観察するだけでは分類できなそうなことは想像つくだろうか。
しかし、本ページを読み終えると皆さんも「平成仮面ライダーの変身ポーズの分類」をできるようになる。
(もっと実用的な例でも良いが)
本ページの内容を理解するための前提条件を記す。まず、下記のページの内容を終えている必要がある。
上記ページで作成した Anaconda 上の仮想環境 tf2 を本ページでも用いる。
なお、上記ページでは用いなかったが本ページでは用いる、というツールを仮想環境 tf2 にインストールしよう。
スタートメニューの「Anaconda3 (64-bit)」から「Anaconda Prompt (tf2)」を起動しよう。
起動したコマンドプロンプトで下記の命令を実行し、pandas というツールをインストールしておこう。
conda install pandas
インストールが終了したらコマンドプロンプトを閉じて構わない。
上記を終えた状態で、本ページのポーズ認識の演習を行うことができる。
ただし、「機械学習」と呼ばれる分野への予備知識が不足しているため、
「実行できたがよくわからなかった」という状態になる可能性がある。
実を言うと、過去の3年生には、本ページの演習を実行する前に、下記の書籍を貸与して一通り学習してもらっていた。
この書籍で扱う「じゃんけんのグー・チョキ・パーの分類」が、本ページの「ポーズ認識」と理論的にほぼ同じ仕組みで動作しているからである。
しかし、学生が上記書籍を読み終わるのに予想以上の時間がかかり、いつまでたってもポーズ認識に入ることができなかった、という反省点が残った。
その反省を踏まえ、最近は逆にポーズ認識のプログラムの実行から入ることにしている。
プログラムを実行し、良く分からなかった点を後から書籍で学習し直す、という手順で進めてみよう。
以上で解説したポーズ認識を実行するためのサンプルファイルであるMediaPipePoseRecogSample.zipをダウンロードしよう。
ダウンロードされたファイルは5つのファイルが圧縮されたファイルであるので展開しなければならない。
ファイルを右クリックし、「すべて展開」を選択する。「すべて展開」という選択肢がない場合、「展開」や「解凍」という語句が含まれる項目を選ぶと良い場合が多いだろう。
展開すると、以下の5ファイルが現れる。解説する順番に並びかえてある。
- mp_pose_record_joints.py
- mp_pose_record_skeletons.py
- mp_pose_skeleton_graph.xlsx
- mp_pose_learn_skeletons.py
- mp_pose_recognize_skeleton.py
この5ファイルを、MediaPipe のプログラムが含まれるフォルダに移動しよう。
「Anaconda で機械学習用の環境を作り、mediapipe による骨格認識を試してみる」に従えば、
mediapipe-python-sample-main フォルダにある、sample_pose.py と同じ位置に移動、という意味である。
以下では、この5ファイルの使い方を解説していく。
mp_pose_record_joints.py は、Spyder (tf2) に読み込ませて使う Python ファイルである。
人間の体にある 33 個のキーポイント (ファイル名では joints とした) の x 座標と y 座標の時間変化を、 Excel で開けるファイルとして保存するためのプログラムである。
このプログラムはポーズ認識に必須というわけではないが、
33 個のキーポイント (joints) の意味を知るためには必要である。
本ページ冒頭で、過去の卒論のポーズ認識について
「両手の y 座標を観察するだけで5つのポーズをある程度分類できる」と述べた。
それを実行できるのもこのプログラムでできる。
さて、Spyder (tf2) でファイルを読み込んだ後、 「実行」→「ファイルごとの設定」を以下のように設定すること。
- 「カスタム設定でファイルを実行」にチェック (古い Spyder では存在しない場合あり)
- コンソール:「外部システムターミナルで実行」にチェック
そしてプログラムを実行すると、通常の MediaPipe の骨格認識と同じように、骨格を緑で表示した映像が開く。
この映像上でキーボードの下記のキーを押すと、座標の時間変化を記録できる。
- r :記録開始。33 個のキーポイントの x 座標と y 座標が時間とともに記録されていく。記録中は映像左上に赤丸が表示される。s キーを押すまで止まらない。
- s :記録終了。プログラムと同じフォルダに「mp_pose_joints_日付と時刻.csv」という名称のデータが保存される。
- q または ESC:プログラム終了。記録中は終了できないので、必ず s を押して記録を終了してから q を押すこと。
例えば、映像上で r キーを押してから 10 秒程度後に s キーを押してみると、
「mp_pose_joints_日付と時刻.csv」という形式のファイルがプログラムと同じフォルダに保存されている。
拡張子が csv のファイルは Excel で開くことができる。ダブルクリックして開くと、下図のようになっている。
一行目に Time、nose_x、nose_y、right eye inner_x、right eye inner_y …と記されており、それぞれ
時間、鼻のx座標、鼻のy座標、右目の内側のx座標、右目の内側y座標 …のようにデータが記録されていることがわかる。
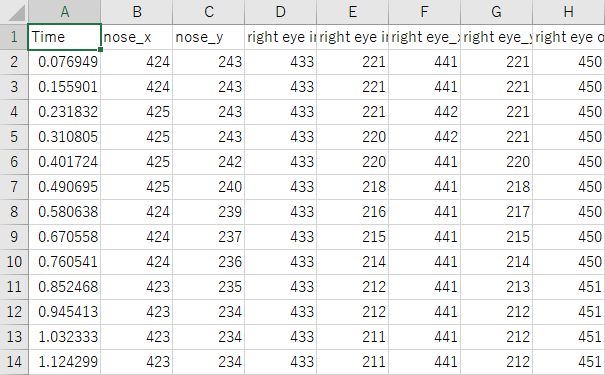
例えば、Time、nose_y、right wrist_y、left wrist_y のデータ(A列、C列、AG列、AI列) を「散布図(直線)」でグラフ表示すると以下のようになる。
鼻のy座標、右手首のy座標、左手首のy座標、の時間変化である。
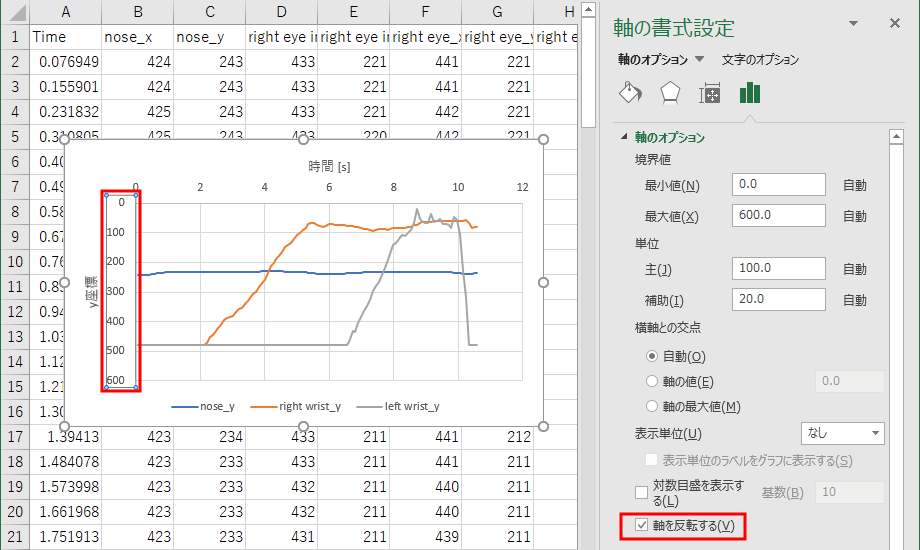
なお、このファイルでの x 座標とy 座標は、映像の左上が原点となっている。そのため、映像の下方向ほど y 座標が大きくなる。
そのため、下図に赤で記したように縦座標で「軸を反転する」という設定を行っている。
グラフの描き方、軸の書式設定の方法は下記を参考にすること。
さて、このグラフを見て何が起こっているかイメージできるだろうか?
約10秒間のデータ記録中、以下の動作を行ったときのグラフである。
まず、カメラの前に座りまず右手を少しずつ上げていく。その後、左手を上げていき、
左手を上げた終わった後に左手を下げてキーボードの s キーを押して記録を終了した様子である。
最初は鼻の高さ (nose_y) よりも下にあった右手首 (right_wrist_y) が、徐々に鼻の高さよりも高くなっていること、
そしてその後、左手首 (left_wrist_y) が徐々に上がって行き、上がりきったらまた下がる様子がグラフから読みとれる。
このように、グラフからその意味するところを正しく読み取れるということは、将来も役立つ重要な能力である。
ところで、保存されたファイルの拡張子は csv であるが、これは comma separated values の略であり、
データをコンマで区切って保存したテキストファイルにすぎない。
実際、csv ファイルをメモ帳で開くと以下のようになっている。
すなわち、csv ファイルというのは Excel 用のファイルというわけではない。
そのため、csv ファイル上でグラフを描いてそれを保存したい場合、ファイルの形式を csv から通常の xlsx 形式に変更しなければ保存できないので注意。
さて、ここからがポーズ認識のために必要なプログラムである。
先程のプログラムは、33個のキーポイント (joints) の座標の時間変化を記録したが、
このプログラムはある一瞬の 33 個のキーポイントの座標を記録する。
その記録は 2 秒ごとに 10 回、すなわち 20 秒間行われる。
なぜ1回だけではなく10回記録するのかは、本ページ後半で明らかに なる。
このファイルも Spyder (tf2) に読み込ませて使う Python ファイルである。
さて、Spyder (tf2) の 「実行」→「ファイルごとの設定」を以下のように設定すること。
- 「カスタム設定でファイルを実行」にチェック (古い Spyder では存在しない場合あり)
- コンソール:「外部システムターミナルで実行」にチェック
実行すると、通常の MediaPipe と同じ映像が開く。このプログラムで開く映像上で受け付けるキー操作は以下の通り。
- r :記録開始。記録開始から 5 秒間は待機状態となり、赤丸が点滅する。その間にカメラから離れ、全身とその骨格が映る位置に移動し、記録したいポーズを取る。
待機状態が終わると、33 個のキーポイントの x 座標と y 座標が 2 秒ごとに 10 回記録される。赤丸の横に、いくつポーズが記録されたかが数字で記される。
プログラムと同じフォルダに「mp_pose_skeleton_日付と時刻.csv」という名称のデータが 10 個保存される。10 回の保存が終わると、データ記録状態は自動的に終了する。
- q またh ESC:プログラム終了。データ記録中は終了できないので 10 個のデータが保存されるのを待ってから q を押すこと。
さて、ファイルを保存し、 10 個のファイルのうち 1 つを開いてみよう。以下のようになっているはずである。
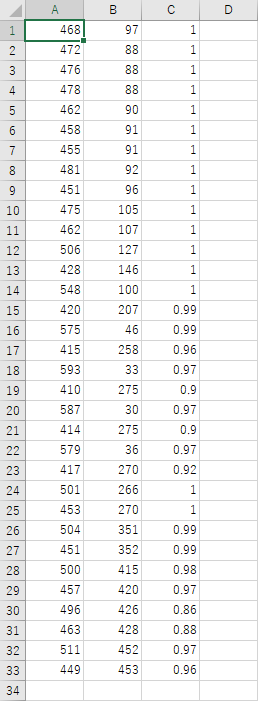
横方向に3列のデータがあるが、これは、
x 座標、y 座標、キーポイントの信頼性(最大1)
の順で並んでいる。
縦方向へは、33個のキーポイントが以下の順で並んでいる。
nose
right eye inner
right eye
right eye outer
left eye inner
left eye
left eye outer
right ear
left ear
mouth right
mouth left
right shoulder
left shoulder
right elbow
left elbow
right wrist
left wrist
right pinky
left pinky
right index
left index
right thumb
left thumb
right hip
left hip
right knee
left knee
right ankle
left ankle
right heel
left heel
right foot index
left foot index
ただし、このファイルの数値だけを見てもどんなポーズが記録されているか、わからないだろう。
それを知るためのファイルが、次の Excel ファイルである。
このファイルは、記録したポーズのイメージをみるための Excel ファイルである。
ダブルクリックして開くと以下のようになっている。
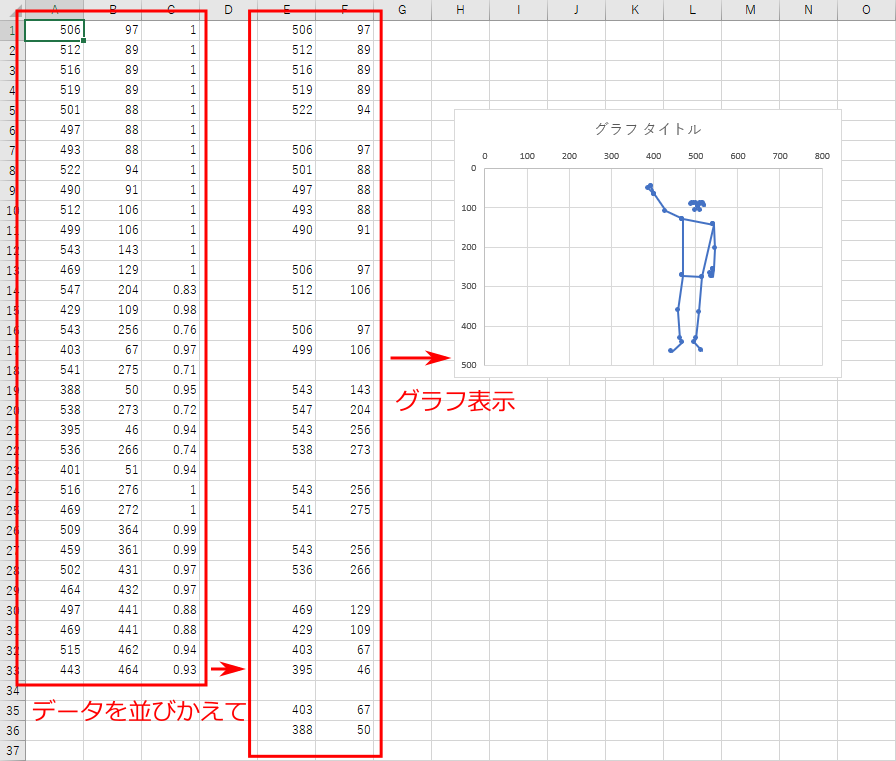
A列からC列の3列にサンプルのデータが入っており、それを並べ替えてポーズを再構成したグラフが示されている。
この Excel ファイルは、mp_pose_record_skeletons.py で記録した「mp_pose_skeleton_日付と時刻.csv」のイメージを理解するのに適している。
下図のように、イメージを知りたい csv ファイルから、3 列分のデータをコピーして
mp_pose_skeleton_graph.xlsx の同じ位置に貼り付けると、データがグラフ表示される、という仕組みである。
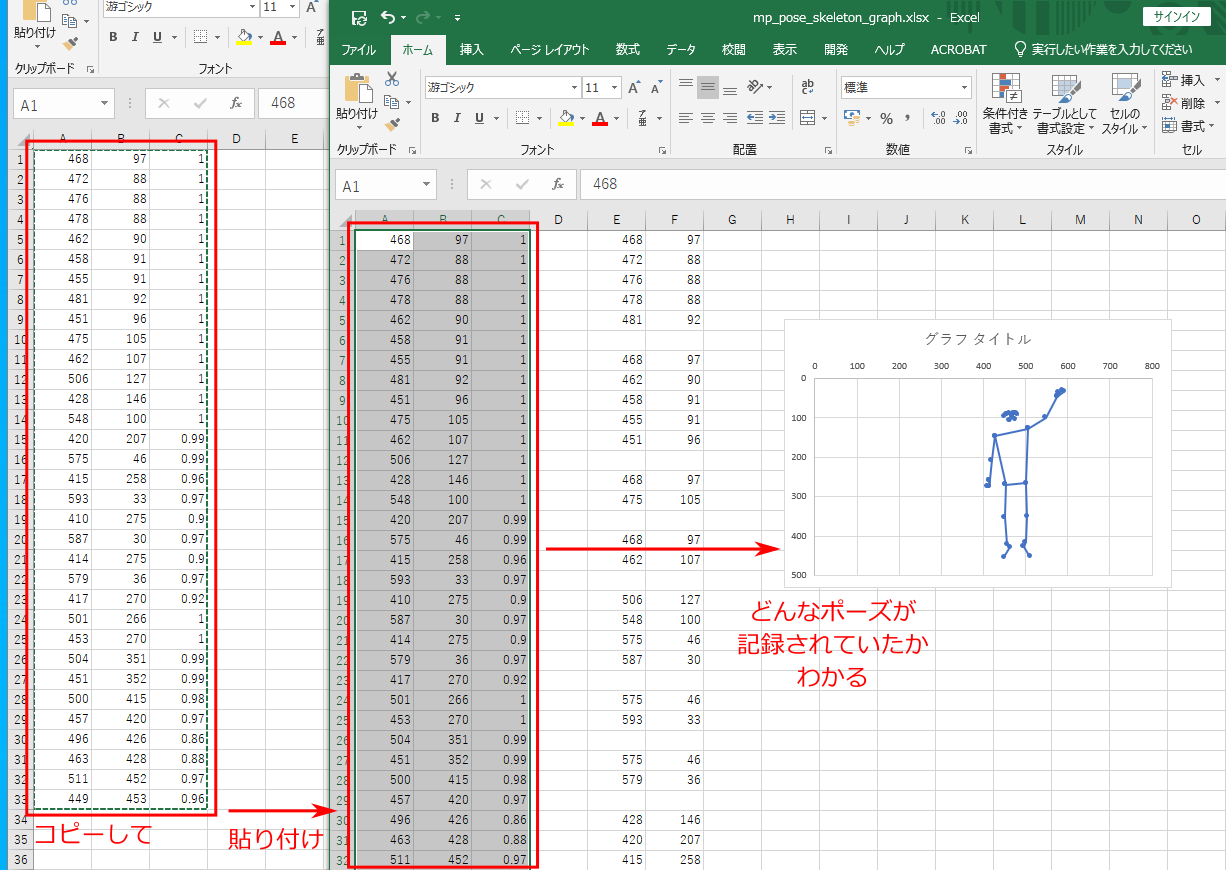
皆さんも mp_pose_record_skeletons.py で自分のポーズを記録し、
それを mp_pose_skeleton_graph.xlsx に貼り付けることで、
自分のとったポーズを Excel ファイルで確認してみよう。
なお、このグラフは横軸の最大値 800、縦軸の最大値が 500 に固定されている。
これは、用いたカメラの解像度が 720 × 480 だったためである。
より解像度の高いカメラを用いていた場合、グラフの軸の最大値を自分で調節すること。
その方法は「Excel を用いたグラフ作成 (実験グラフ設定)」に記されている。
さて、2秒ごとに10個のポーズを保存する mp_pose_record_skeletons.py は、ポーズ認識の学習用データを用意するのに適している。その方法を解説しよう。
まず、どのようなポーズを認識するか、およびその個数をあらかじめ決めておく。
例えば過去の卒論の場合だと、「直立」、「右手上げ」、「左手上げ」、「両手腰」の4つであった。
このとき、「直立」はポーズをしていない「非ポーズ状態」とも解釈できる。
言い替えると、過去の卒論の場合だと、ポーズの個数は
「直立 (非ポーズ状態)」、「右手上げ」、「左手上げ」、「両手腰」の4つ、ということになる。
そのような数え方で、ポーズの数が N 個であるとする。
そして、それぞれのポーズを今後「クラス i (i=0~N-1)」と呼ぶことにする。
過去の卒論の場合だと N=4 で、クラス0 からクラス 3、ということである。
次に、mp_pose_record_skeletons.py が存在するのと同じフォルダに「0」、「1」、「2」…「N-1」の計 N 個のフォルダを作成する。
例えば N=4なら、「0」、「1」、「2」、「3」の 4 フォルダを用意するということである。
なお、数字は全角の数字ではダメで、半角の数字でなければならない。
すなわち、日本語入力ソフトが下記の「直接入力」の状態でフォルダを作成するということ。
そして、各フォルダの数字 i にあらかじめ考えておいたポーズを割り当てる。
すなわち、クラス i のポーズの学習データをフォルダ「i」に保存するようにする。
それを実現するための流れを解説すると以下のようになるだろう。
- mp_pose_record_skeletons.py を実行して r キーを押し、10個のポーズデータを保存する。
このとき、10 個のポーズデータは全て同じポーズのデータとする (例えば「右手上げ」ポーズを 10 個、ということ)。
ただし、10 個のデータを保存する間、微妙に手の角度を替えたりカメラへ向かう角度を微妙に替えるなどし、
同じポーズでも様々なバリエーションのデータが取れるようにする。
- 保存された 10 個の csv ファイルを、フォルダ 0 に移動する。
すなわち、保存したポーズをクラス 0 のポーズと見なすということ。
なお、フォルダ内に移動して良いのは「mp_pose_skeleton_日付と時刻.csv」というファイルだけである。
「mp_pose_joints_日付と時刻.csv」というファイルを移動してはならない。
- 再び r キーを押し、別のポーズに対する 10 個のポーズデータを保存する。
(例えば、先程が「右手上げ」ポーズを 10 個だったのなら、今度は「左手上げ」ポーズを 10 個、ということ)
- 保存された 10 個の csv ファイルを、フォルダ 1 に移動する。
- 以上のプロセスを、フォルダ N-1 が埋まるまで繰り返す
以上の作業により、フォルダ 0 ~ N-1 に、それぞれ少なくとも 10 個ずつのデータが格納されることになる。
各フォルダ内のデータの個数は 10 個である必要はなく、多ければ多い程良い。
特に、「非ポーズ」のデータは様々なバリエーションの非ポーズデータがたくさんあった方がよい。
しかし、練習ならば 10 個ずつのデータでも問題はないだろう。
さて、Nクラスのポーズを分類 (認識) するために、データを含んだフォルダ 0 ~ N-1 を用意できたはずである。
それを mp_pose_learn_skeletons.py により学習してみよう。これは Spyder (tf2) に読み込ませて使う Python ファイルである。
Spyder (tf2) で mp_pose_learn_skeletons.py を開いたら、
Spyder (tf2) の 「実行」→「ファイルごとの設定」を以下のように設定すること。
- 「カスタム設定でファイルを実行」にチェック (古い Spyder では存在しない場合あり)
- コンソール:「外部システムターミナルで実行」にチェック
- 一般設定:「コマンドラインオプション」にチェックして result.h5 を記述
なお、コマンドラインオプションの「result.h5」とは、
「コマンドラインオプション」のチェックボックスにチェックし、
その横の記入欄にresult.h5 と記す、ということである。
result.h5 が、学習結果を保存するためのファイル名となる。
拡張子が「h5」であればファイル名は何でも構わない。
ただし、学習後の認識にそのファイルを用いるので、ファイル名は忘れないようにしよう。
以上の設定のもとプログラムを実行すると学習が行われる。
どのような学習データを用意したかにもよるが、典型的には下図のような損失の時間変化を示すグラフが現れる。
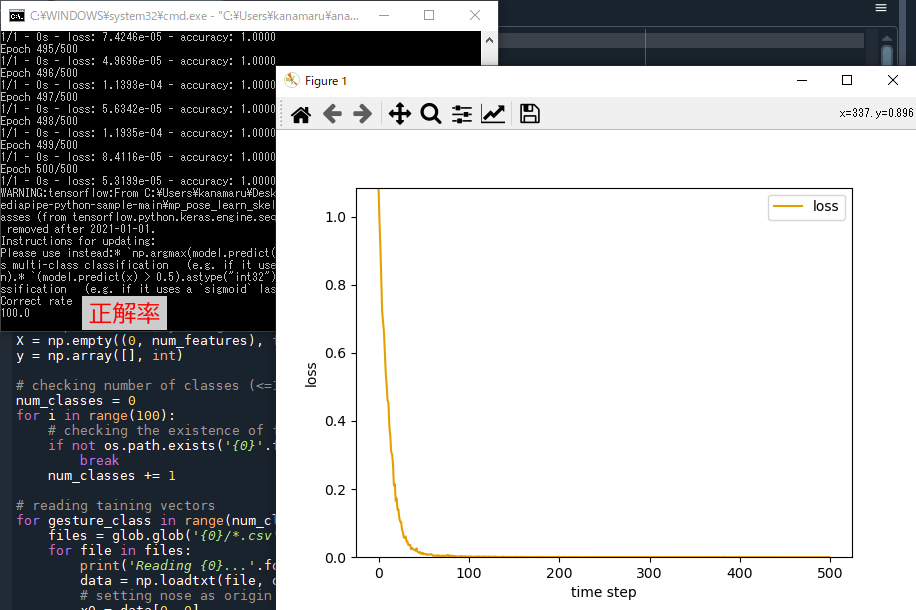
このグラフを閉じるとプログラムは終了し、mp_pose_learn_skeletons.py と同じ位置に result.h5 が保存されている。
なお、グラフが表示されずに以下のエラーが表示される場合があるかもしれない。
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5 already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
この場合でも学習済みのファイル result.h5 は適切に保存されているのでそれほど心配する必要はない。
グラフも正しく表示されるようにしたければ、このプログラムの2行目「import os」の次の行に
下記のように「os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"」という行を追加し、
プログラムを上書き保存 (Ctrl+S) し、プログラムを再実行すればよい。
import os # ←これは既存の行
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
それにより、正しくグラフが表示されるようになるだろう。
さて、学習が終わったら、それを mp_pose_recognize_skeletons.py によりに認識させてみよう。
これはSpyder (tf2) に読み込ませて使う Python ファイルである。
Spyder (tf2) で mp_pose_recognize_skeletons.py を開いたら、
Spyder (tf2) の 「実行」→「ファイルごとの設定」を以下のように設定すること。
- 「カスタム設定でファイルを実行」にチェック (古い Spyder では存在しない場合あり)
- コンソール:「外部システムターミナルで実行」にチェック
- 一般設定:「コマンドラインオプション」にチェックして result.h5 と記述
コマンドラインオプションの「result.h5」の部分は学習結果を保存したファイル名であるので、皆さんが保存時に決めたファイル名にして欲しい。
なお、このプログラムで表示される映像上で受け付けるキーボード入力は以下の通りである。
MediaPipe のプログラム同様、映像上に姿勢を表す線が表示されるが、その上に認識されたポーズのクラス番号が「class 0」のように白文字で表示される。
カメラの前に立ってポーズ保存時にしたポーズをとり、画面上に正しいクラス番号が確認されるか確認してみよう。
正しいクラス番号が表示されれば、ポーズ認識に成功しているということである。
意図した通りにポーズを認識できただろうか?
以上、ポーズ認識を実行するためのサンプルファイルの使い方を解説した。
同様のポーズ認識を、「全身の骨格」に対してではなく「手の骨格」に対して行うサンプルファイルMediaPipeHandRecogSample.zipも用意した。
こちらも全く同じ手順で実行できる。以下の通り試してみよう。
まず、圧縮ファイルを展開すると、手認識用の以下の5ファイルが現われる。全身の骨格認識のファイル名の「_pose_」の部分が
「_hand_」に変わっているだけで、役割はそれぞれ全く一緒のものである。
- mp_hand_record_joints.py
- mp_hand_record_skeletons.py
- mp_hand_skeleton_graph.xlsx
- mp_hand_learn_skeletons.py
- mp_hand_recognize_skeleton.py
これらの実行ファイルを実行するため、以下の手順に従おう。
従わないと、全身の認識用と手の認識用でファイルが混乱してしまう可能性があるからである。
まず、皆さんが全身の認識を実行したファイルが存在するフォルダは「mediapipe-python-sample-main」という名前のはずである。
このフォルダをコピー&貼りつけにより複製しよう。Windows のデフォルトでは、複製されたフォルダの名前は
「mediapipe-python-sample-main - コピー」となっているはずである。
すなわち、皆さんが全身の認識を実行したフォルダが「mediapipe-python-sample-main」と「mediapipe-python-sample-main - コピー」の2つ存在することになる。
このうち、後者の「mediapipe-python-sample-main - コピー」の方のフォルダ名を変更しよう。
ここでは手認識を意味する「hand-recognition」という名称に変更するものとし、以後、この名前で解説を続ける。
すなわち、「mediapipe-python-sample-main」が全身認識用フォルダ、「hand-recognition」が手認識用フォルダということである。
(もちろん、全身認識用の「mediapipe-python-sample-main」のフォルダ名もお好みで変えて構わない)
さて、エクスプローラー上で「hand-recognition」フォルダ内に入ろう。この中にある全身認識用のもの、すなわち以下のファイルとフォルダを削除しよう。
もちろん、このフォルダを手認識用のフォルダとするためである。
- 皆さんのポーズを格納した 0 ~ N の数字名のついたフォルダ全て
- 学習結果を格納した result.h5
- ファイル名が「mp_pose_」で始まるもの全て
以上のファイルの削除が済んだら、この「hand-recognition」フォルダのこの位置 (sample_pose.py が存在する位置) に、
先程展開した手認識用のファイル (「mp_hand_」で始まる 5 ファイル) を移動しよう。
以上で手認識の演習を行う準備は完了である。
本ページの冒頭に戻り、演習をおこなってみよう。
本ページでは最初に mp_pose_record_joints.py の解説から始まる。
これを mp_hand_record_joints.py の解説と読み替えて演習を行う、ということである。
そのようにして、手でもポーズ認識を実現して欲しい (わかりやすいところでは、グー、チョキ、パーの認識だろうか)。
ここで紹介したプログラムは、全て画面の大きさを変えたり最大化したり、ということができるようになっている。
これは、プログラム中に下記の行があるためである。'xxxx' の部分はプログラムにより異なる。
cv.namedWindow('xxxx', cv.WINDOW_NORMAL)
この行を消すとか、先頭に「#」をつけて無効化すると、カメラ映像を拡大縮小できなくなることがわかるだろう。
ウインドウや映像のサイズを自由に変更できるのは便利であるが、映像の横と縦の比 (アスペクト比) が変わってしまうのが問題である。
例えば、PCについているカメラは、多くの場合デフォルトでアスペクト比が 4:3 の映像が取得される。典型的には 640x480 である。
一方、皆さんのPCの画面はのアスペクト比は、多くの場合 16:9 や 16:10 などのように横長のワイド画面になっている。
この状況でウインドウを最大化すると、映像は横長に拡大されることはわかるだろう。
映像のアスペクト比を 4:3 に保ったまま映像を最大化するのはそれほど簡単ではない。
映像のアスペクト比を 4:3 に保ちたければ、cv.namedWindow('xxxx', cv.WINDOW_NORMAL) の行を無効化して、映像サイズを固定するのが最も安全である。
しかし、どうしても
「プログラム実行中にアスペクト比を保ったまま大きい映像を表示したい」場合、
cv.namedWindow('xxxx', cv.WINDOW_NORMAL) の行を無効化したまま、
cv.imshow('xxxx', debug_image)
などの行を
cv.imshow('xxxx', cv.resize(debug_image, (1280, 960)) )
などのようにして、
「640x480 の画像を強制的に 1280x960 にして表示」などとするのが最も簡単だろう
(1280x960 の部分は、4:3 の数字ならば何でも良い)。
画面に表示する映像を拡大しているだけなので、認識率などには影響がないことに注意。
3年生向けページに戻る