#include <iostream>
int main(int argc, char* argv[])
{
// 電源、チャンネル、ボリューム変数の宣言
int power, channel, volume;
// 電源、チャンネル、ボリュームの初期化
power = 0;
channel = 1;
volume = 0;
// 値のセット
power = 1; // 電源オン
channel = 8;
volume = 10;
// 状態の表示
if(power == 1){
std::cout << "電源はオンです。";
std::cout << "チャンネルは" << channel << "です。";
std::cout << "ボリュームは" << volume << "です。\n";
}else{
std::cout << "電源はオフです。\n";
}
return 0;
}
|

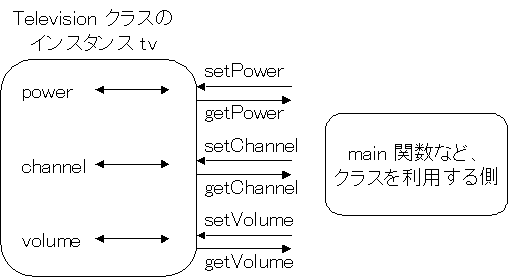
| Television.h |
クラス開発者が記述する。クラス開発者はメンバ関数のみをクラス利用者に公開し、 内部にあるデータは隠蔽する。 |
| Television.cpp | |
| TVProject.cpp (main 関数など) |
クラス利用者が記述する。クラス利用者はクラス開発者と同じとは限らない。 開発者から公開されたメンバ関数を活用し、必要な機能を実装する。 |