Swinging up a Pendulum by Reinforcement Learning
After downloading tp_rl_app.jar, please execute it by double-clicking, or typing "java -jar tp_rl_app.jar".
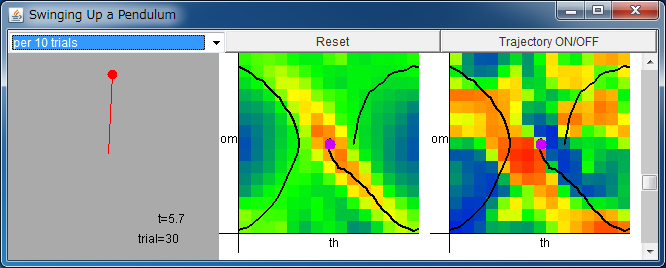
From left: State of the pendulum / Critic / Actor
The range of horizontal axes of critic/actor is
-π <θ < π, and
the range of vertical axes of critic/actor is
-2π <ω < 2π.
The colors of the approximated functions denote the following values.
blue: negative, green: 0, red: positive.
By clicking the fields of critic/actor, you can set the initial state of the pendulum.
By regulating the scroll bar, you can change the value of mass.
After about from 50 to 100 trials of learning,
the control system will be able to swing up the pendulum.
If the above application does not start, please install OpenJDK from adoptium.net.
Let us consider a task to swing up a pendulum using the reinforcement learning.
The dynamics of a pendulum with a limited torque is written as
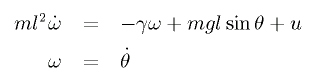
Our goal is to construct a controller which observes
the state (θ, ω) of a pendulum
and gives an appropriate value of torque u to the pendulum.
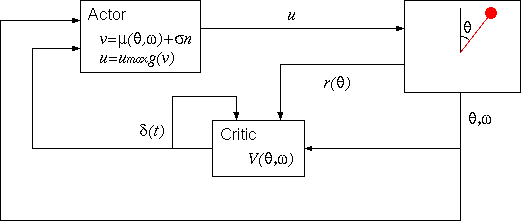
Under the scheme of the reinforcement learning,
the controller can be constructed as shown in the following figure.
The reward r is defined as r(θ) = cos θ
so that the upright state receives a maximal reward.
The cumulated future reward following the policy u is defined as
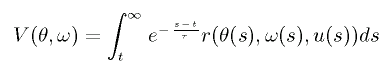
By searching large values of V(θ, ω),
we can obtain the upright state of the pendulum.
However, V(θ, ω) is an unknown function,
so we must perform a function approximation to obtain
V(θ, ω).
It is known that V(θ, ω) can be correctly
learned by minimizing the temporal difference error δ(t).
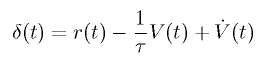
The unit which approximates
V(θ, ω) is called "critic".
On the other hand, the unit which determines the input u
according to (θ, ω) is called "actor"
(n is a noise).
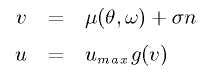
μ(θ, ω) is also an unknown function,
we must perform a function approximation for μ(θ, ω).
Also in this case, μ(θ, ω)
can be correctly approximated by minimizing the temporal difference error δ(t).
In this applet, for the learning of the critic,
we use TD(λ) method for continuous time and space,
and, for the learning of the actor, we use policy gradient method.
This page is based on the following papers.
- Kenji Doya
"Reinforcement learning in continuous time and space"
Neural Computation, vol.12, 219-245 (2000).
- R.J. Williams
"Simple statistical gradient-following algorithms for connectionist reinforcement learning"
Machine Learning,vol.8, pp.229-256, (1992).
<< Cart-Pole Balancing by Reinforcement Learning
Back to Takashi Kanamaru's Web Page