第十三回-02 何故クラスを使うのか?
前ページでテレビクラスを実装し、main 関数から利用してみた。
あの中にオブジェクト指向プログラミングのエッセンスがある程度詰まっていると言える。
その意義を理解するため、先程の例を手続き型プログラミングの手法で書いてみたのが以下のプログラムである
(皆さんは実行する必要はない)。
#include <iostream>
using namespace std;
int main(void)
{
// 電源、チャンネル、ボリューム変数の宣言
int power, channel, volume;
// 電源、チャンネル、ボリュームの初期化
power = 0;
channel = 1;
volume = 0;
// 値のセット
power = 1; // 電源オン
channel = 8;
volume = 10;
// 状態の表示
if(power == 1){
cout << "電源はオンです。";
cout << "チャンネルは" << channel << "です。";
cout << "ボリュームは" << volume << "です。\n";
}else{
cout << "電源はオフです。\n";
}
}
多少プログラム自体を簡略化して記述したが、内容は理解できるだろうか。
単に変数を3つ宣言し、値を代入したあと値を表示したというだけの内容で、「それがどうした」というプログラムになっている。
この手続き型プログラミングと比べると、クラスを用いたプログラミングの特徴として、まず、以下が挙げられる。
- 変数をクラスという枠でくくることで、変数同士の結び付きが強まり、意味が明確になる
手続き型プログラミングの場合は、電源、チャンネル、ボリュームはそれぞれ単なる変数であるので、
それぞれがテレビの構成要素であることが伝わりにくい。それに比べるとクラスを用いた場合は
それら3つがまとまっているので意味が明確になっている。
次にクラスを用いたプログラムの特徴には以下がある。
- 変数 (データメンバ) に対する処理をもクラスに含めることで、その処理と変数との結び付きが強くなり、意味が明確になる
まず、上の例では、テレビの電源をオンにする処理は「power = 1;」に該当するが、
これは単に変数に1を格納しているだけであり、
「電源をオンにしている」という意味が伝わりにくい。
一方、クラスを用いた例での「tv.setPower(1);」は、関数名をわかりやすくつけたこととも相まって「電源に1をセットしている」ことがわかりやすい。
(さらに PowerOn() とか PowerOff() というメンバ関数を作ればさらにわかりやすかったかもしれない)
このように、変数を宣言したり、変数に値を格納する、というだけの処理であっても、
手続き型プログラミングとオブジェクト指向プログラミングは考え方が全く異なり、
オブジェクト指向プログラミングではいかに意味を明確にするか、に注意が払われていることがわかる。
さらに、オブジェクト指向プログラミングの特徴を探っていこう。
まず、テレビクラスを利用する main 関数を再掲しておこう。
int main(void)
{
Television tv; // Television クラスの変数 tv を宣言
// クラスを「新しい型」として用いている
// この時点でコンストラクタが呼ばれる
tv.printStatus(); // 確認のために状態表示
tv.setPower(1); // 電源オン
tv.setChannel(8); // 8チャンネルにセット
tv.setVolume(10); // ボリュームを10に
tv.printStatus();
tv.setChannel(4); // 4チャンネルにセット
tv.printStatus();
}
ここで一つ気づいて欲しいことがある。
テレビ関数には、データメンバとして power、channel、volume があったはずだが、main 関数には全く登場していないことである。
(これを「main 関数からアクセスされていない」、という言い方をする)
その替わりに利用されているのが、setPower、setChannel、setVolume といったメンバ関数である。
これらのことを「テレビクラスが提供するインターフェイス」、という言い方もする。
また、今回のプログラムではそもそも main 関数から直接 power、channel、volume という変数には直接アクセスできない仕組みにしている。
このことは重要なので図で表しておこう。下図のように、Television クラスの変数 (インスタンス) tv があったとき、
その内部にある変数 power、channel、volume にはクラス利用者にアクセスさせず、
setXXX 関数 (setter という) や getXXX 関数 (getter という) を用いてアクセスさせる、というのが基本的な考え方である。
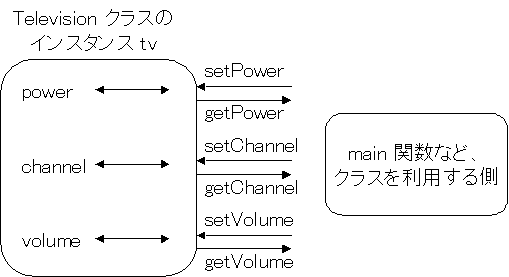
現実にテレビを持っている方は多いだろうが、実際のテレビでも電源、チャンネル、ボリュームはリモコンや前面パネルでアクセスするだけで、
テレビの中でそれらがどう実現されているかはわからない人がほとんどだろう。
それと同じことをプログラミングでも行っているわけである。
変数に直接アクセスさせない理由は、変数があらゆる場所から編集可能だと、思いもかけないバグの温床になる可能性があるからである。
そのため、setter や getter を使うよう、変数のアクセスに制限をかけている、というわけである。
これをデータ隠蔽 (情報隠蔽、カプセル化などとも) という。
ここで、オブジェクト指向プログラミングにおいて、「誰がプログラミングするのか」に関する前提を紹介しておこう。
下の表のように、クラスを開発するクラス開発者と、クラスを利用するクラス利用者は異なる、と考えるとデータ隠蔽の考え方は理解しやすい。
|
クラスの宣言
|
クラス開発者が記述する。クラス開発者はメンバ関数のみをクラス利用者に公開し、
内部にあるデータは隠蔽する。
|
|
クラスの実装
|
|
main 関数など
|
クラス利用者が記述する。クラス利用者はクラス開発者と同じとは限らない。
開発者から公開されたメンバ関数を活用し、必要な機能を実装する。
|
つまり、上の図と合わせて考えると、クラス開発者はクラスの内部の動作の実装に注力し、
クラス利用者は公開されたメンバ関数の活用に注力する、というわけである。
もちろん、このような講義や、個人で作る小さなプログラムの場合は
一人の人がクラス開発者とクラス利用者の一人二役をこなすのだが、
その場合もクラス開発者になるのかとクラス利用者になるのかで頭を切替える、ということである。
さて、本ページで登場した「オブジェクト指向プログラミングを用いるメリット」を再掲しておくと以下の通り。
- 変数をクラスという枠でくくることで、変数同士の結び付きが強まり、意味が明確になる
- 変数 (データメンバ) に対する処理をもクラスに含めることで、その処理と変数との結び付きが強くなり、意味が明確になる
- データ隠蔽により変数のアクセスに制限をかけ、バグの危険を減らす
上の2つ「意味が明確になる」というのは保守性が高まる (メンテナンスしやすくなる) という言い方もできるかもしれない。
なお、今回紹介できるのはここまでであるが、「データ隠蔽」の他に、「継承」、「多態性」を加えて
オブジェクト指向の三大要素、と呼ぶことがあることを付記しておく。
さて、もちろんこのようなメリットがある半面、前ページで見たようにオブジェクト指向プログラミングでは記述量が増えるというデメリットはある。
しかし、大規模なプログラミングでは、記述量の増大というデメリットよりも保守性と安全性を高めるというメリットの方が大きくなるだろう。
←テレビクラスを作ってみよう
/
課題→
オンラインコンパイラで C/C++ を自習しように戻る